
티스토리 뷰
Message Queue (Apach Kafka)
A long~ time ago 는 아니고, 사알짝 머언 옛날부터.. 🐅
많은 기업에서 Message Queue 를 아주 활발하게 사용했다고 하는데..
Message Queue가 뭣인지 한번 탐구해 보려고 한다. 🕵
다들 돋보기 들고 따라와 보시게! 🤠🔎
.
참고로, 다양한 Message Queue 중 높은 처리량과 좋은 성능을 지닌 Kafka 중심의 설명이 될 것 같다.🧐
최범균님의 kafka 조금 아는 척하기 영상이 정말 많은 도움이 되었다.
메시지 지향 미들 웨어(Message Oriented Middleware: MOM)는 비동기 메시지를 사용하는 다른 응용 프로그램 사이에서의 데이터 송수신을 의미
- MOM을 구현한 시스템이
메시지 큐(Message Queue: MQ)
.
프로그래밍에서 MQ는 프로세스 또는 프로그램 인스턴스가 데이터를 서로 교환할 때 사용하는 방법
- 데이터 교환 시 시스템이 관리하는 메세지 큐를 이용하는 것이 특징
- 서로 다른 프로세스나 프로그램 사이에 메시지를 교환할 때
AMQP(Advanced Message Queueing Protocol)을 이용- AMQP : 메세지 지향 미들웨어를 위한 open standard application layer protocol
.
서로 다른 부분으로 분리된 대규모 애플리케이션이 메시지 큐를 사용하여 비동기식으로 통신
- 메시지 처리 방법을 활용하여 유지 보수 및 확장이 용이한 시스템을 구축할 수 있음
.
장점
- 비동기(Asynchronous) : Queue에 넣기 때문에 나중에 처리 가능
- 비동조(Decoupling) : 애플리케이션과 분리 가능
- 탄력성(Resilience) : 일부가 실패 시 전체에 영향을 받지 않음
- 과잉(Redundancy): 실패할 경우 재실행 가능
- 보증(Guarantees): 작업이 처리된 걸 확인 가능
- 확장성(Scalable): 다수의 프로세스들이 큐에 메시지를 보낼 수 있음
MQ는 대용량 데이터를 처리하기 위한 배치 작업이나, 채팅 서비스, 비동기 데이터를 처리할때 주로 사용
사용자/데이터가 많아지면 요청에 대한 응답을 기다리는 수가 증가하다가 나중에는 대기 시간이 지연되어서 서비스가 정상적으로 되지 못하는 상황이 오게 된다.
그러므로 기존에 분산되어 있던 데이터 처리를 한 곳으로 집중하면서 메시지 브로커를 두어서 필요한 프로그램에 작업을 분산시키는 방법
.
사용
- 다른 프로그램의 API로 부터 데이터 송수신
- 다양한 애플리케이션에서 비동기 통신
- 이메일 발송 및 문서 업로드
- 많은 양의 프로세스 처리
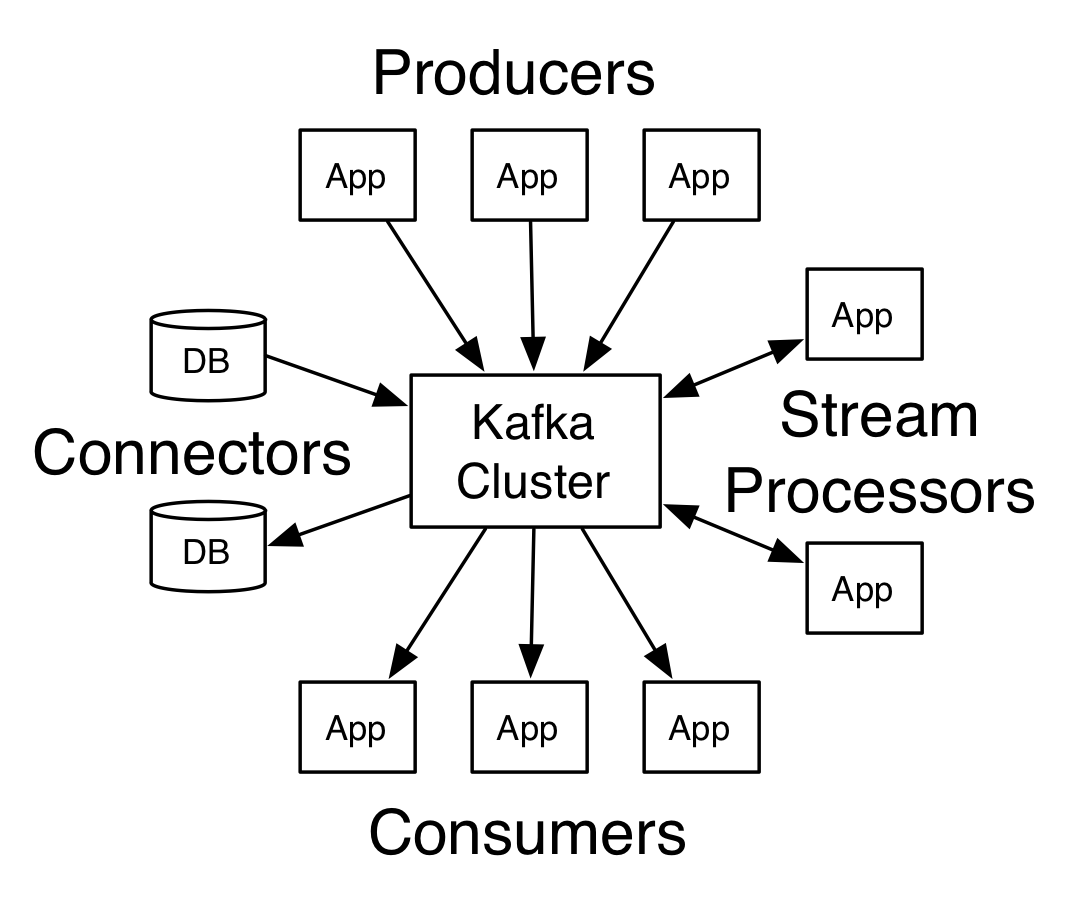
Apache Kafka
기본구조
kafka cluster: 메시지(이벤트) 저장소- 여러개의
브로커(ex. server)로 구성 - 브로커의 역할은 메시지를 나누어 저장, 이중화 처리, 장애 대체 등
- 여러개의
zookeeper cluster(앙상블):kafka cluster를 관리kafka cluster관련 정보가 기록
Producer:kafka cluster에 메시지(이벤트)를 넣는 역할Consumer: 메시지(이벤트)를 카프카에서 읽는 역할
Topic & Partition
Topic : 메시지를 저장(구분)하는 단위
- ex. 주문용, 결제용, 관리용 ..
Producer는 메시지를 kafka에 저장 시 어떤 Topic에 저장해달라고 요청Consumer는 어떤 Topic에서 메시지를 읽어 올지 요청Producer,Consumer는 토픽을 기준으로 메시지를 주고받음
Partition : 메시지를 저장하는 물리적인 파일
Topic은 한 개 이상의Partition으로 구성- 추가만 가능한 append-only 파일
- 각 메시지 저장 위치는
offsetProducer가 넣은 메시지는 Partition 맨 뒤에 추가Consumer는 offset 기준으로 순서대로 메시지 리딩
- 메시지는 삭제되지 않고, 설정에 따라 일정 시간 뒤 삭제
Producer는 라운드 로빈 or 키로 Partition 선택- 같은 키를 갖는 메시지는 같은 Partition에 저장 (같은 키는 순서 유지)
- 한 개의
Partition은Consumer group내 한 개의Consumer와만 연결 가능- Consumer group 내에 있는
cunsumer들이 같은 partition을 공유할 수 없음- 단, 다른 그룹에 있는
Consumer와는 공유 가능
- 단, 다른 그룹에 있는
Consumer와Partition은 1:1 관계이므로Consumer group기준으로partition의 메시지가 순서대로 처리되는 것을 보장
- Consumer group 내에 있는
성능
Partition파일은OS 페이지 캐시를 사용하여 성능 향상- Partition에 대한 파일 IO를 메모리에서 처리
- 서버에서 페이지 캐시를 kafka만 사용해야 성능에 유리
Zero Copy- 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사
- 단순한 브로커의 역할
- 메시지 필터, 재전송 등과 같은 일을 브로커가 하지 않고, Consumer-Partition 매핑 관리만 수행
배치 처리- Producer : 일정 크기만큼 메시지를 모아서 전송
- Consumer : 일정 크기만큼 메시지를 모아서 조회
수평 확장성- 장비 용량에 한계가 올 경우, 브로커, 파티션 추가
- 컨슈머가 느릴 경우, 컨슈머, 파티션 추가
장애 대응replica:Partition의 복제본replication factor(토픽 생성 시 설정한 개수)만큼Partition복제본이 각 브로커에 생성
Producer,Consumer는 리더 브로커를 통해서 메시지를 처리하고 팔로워는 리더의 파일을 복제- 리더가 속한 브로커에 장애 발생 시 다른 팔로워가 리더로 임명
Producer
Properties prop = new Properties(); // Producer 설정 정보
prop.put("bootstrap.servers", "kafka01:9092,kafka01:9092,kafka01:9092"); // kafka host, server
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<Integer, String> producer = new KafkaProducer<>(prop);
// message 전송 (ProducerRecord : 브로커에 전송할 메시지)
producer.send(new ProducerRecord<>("topicname", "key", "value"));
producer.send(new ProducerRecord<>("topicname", "value"));
producer.close();\1. producer.send() 호출
\2. 메시지를 Serializer byte 배열로 변환
\3. 메시지의 토픽/파티션 결정
\4. Sender가 메시지를 보내는 동안 배치에 메시지를 모으고
\5. 배치에 메시지가 찼는지에 상관없이 Sender는 순서대로 브로커에게 배치 메시지 전송
- 배치와 Sender 관련 설정에 처리량 차이가 발생
batch size: 배치가 size만큼 차면 전송linger.ms: 전송 대기 시간(default 0)- 대기 시간이 없으면 배치를 바로 전송, 설정 시 시간만큼 대기 후 배치를 전송
- 지연 시간을 주면 한 번에 보낼 수 있는 메시지의 양이 많아지므로 처리량 증가
전송 결과 확인
Future
- 블로킹으로 배치 효과가 떨어져 처리량 저하
- 처리량이 낮아도 되는 경우에만 사용
Future<RecordMetadata> f = producer.send(new ProducerRecord<>("topic", "value"));
try {
RecordMetadata meta = f.get(); //블로킹
} catch(ExecutionException ex) {
}Callback
- 처리량 저하 없음
producer.send(new new ProducerRecord<>("topic", "value"),
new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception ex) {
//Exception을 받을 경우 전송 실패
}
});전송 보장
ack : 전송 보장을 위한 설정
- ack = 0
- 서버 응답을 기다리지 않음 (전송 보장 zero)
- 처리량은 높아지지만 메시지 전송 실패 여부 확인 불가
- ack = 1
- 파티션의 리더에(만) 저장되면 응답
- 리더 장애 시 메시지 유실 가능성
- ack = all (-1)
- 엄격한 전송 보장
- 모든 리플리카에 저장되면 응답
- 브로커 설정
min.insync.replicas에 따라 변동- 저장에 성공했다고 응답할 수 있는 동기화된 리플리카 최소 개수
- 주의) 리플리카 개수와 동일하게 설정 시 팔로워 중 한 개라도 장애가 있으면 리플리카 부족으로 저장 실패
- 브로커 설정
에러 유형
- 전송 전
- 직렬화 실패
- 프로듀서 자체 요청 크기 제한 초과
- 프로듀서 버퍼가 차서 기다린 시간이 최대 대기 시간 초과
- ...
- 전송 과정
- 전송 타임 아웃
- 파티션 리더 장애로 인한 새 리더 선출 진행 시
- 브로커 설정 메시지 크기 한도 초과
- ...
에러 대응
재시도
- 재시도 가능한 에러는 재시도 처리 (타임 아웃, 일시적 파티션 리더 부재)
Producer는 자체적으로 브로커 전송 과정 시 에러가 발생하면 재시도 가능한 에러에 한해 재전송 시도(retries속성 참고)- send() 메서드에서 Exception 발생 시 타입에 따라 send() 재호출
- send() 메서드에 전달한 Callback에서 Exception 응답 시 타입에 따라 send() 재호출
- 주의)
- 무한 재시도는 X
- 브로커 응답이 늦게 와서 재시도할 경우 중복 발송 가능성 (
enable.idempotence속성 참고) - 재시도 순서 (
max.in.flight.requests.per.connection속성 참고)- 블로킹 없이 한 커넥션에서 전송할 수 있는 최대 전송 중인 요청 개수
- 1보다 클 경우 재시도 시점에 따라 메시지 순서 변동 가능성
- 전송 순서가 중요할 경우 1로 지정
기록
- 향후 처리를 위한 기록
- 파일, DB 등을 이용한 실패 메시지 기록
- send() 메서드에서 Exception 발생 시
- send() 메서드에 전달한 Callback에서 Exception 응답 시
- send() 메서드가 리턴한 Future.get() 메서드에서 Exception 발생 시
- 파일, DB 등을 이용한 실패 메시지 기록
Consumer
특정 토픽의 파티션에서 레코드 조회
Properties prop = new Properties();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("group.id", "group1"); //컨슈머 그룹
prop.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //역직렬화 설정
prop.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);
consumer.subscribe(Collections.singleton("simple")); //토픽 구독
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMailis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value() + ":" + record.topic() + ":" + record.partition() + ":" + record.offset());
}
}
consumer.close();- 토픽 파티션은 그룹 단위 할당
- Consumer 개수가 파티션 개수보다 커지면 안 된다. (노는 Consumer 발생)
- 처리량 저하로 Consumer 개수를 늘려야 한다면 파이션 개수도 늘려야 함.
Commit & Offset
Consumer Poll
- 이전에 Commit 한 offset이 있다면, 그 offset 이후의 레코드를 조회
- 마지막으로 읽은 offset을 commit
- 위 과정의 반복
커밋된 offset이 없을 경우
- 처음 접근하거나 커밋한 offset이 없을 경우
auto.offset.reset설정 사용earliest: 맨 처음 오프셋 사용latest: 가장 마지막 오프셋 사용(default)- none : 컨슈머 그룹에 대한 이전 커밋이 없으면 Exception 발생
Consumer Setting
조회에 영향을 주는 설정
fetch.min.bytes: 조회 시 브로커가 전송할 최소 데이터 크기- default: 1
- 값이 클수록 대기 시간은 늘어나지만 처리량 증가
fetch.max.wait.ms: 조회할 데이터가 최소 크기가 될 때까지 대기할 시간(브로커가 리턴할 떄까지 대기하는 시간)- default: 500ms
max.partition.fetch.bytes: 파이션당 브로커(서버)가 리턴할 수 있는 최대 크기- default: 1048576 (1MB)
Auto Commit
enable.auto.committrue: 일정 주기로 Consumer가 읽은 offset commit (default)false: 수동으로 커밋
auto.commit.interval.ms- 자동 커밋 설정 시 주기 세팅
- default: 5000ms (5초)
- poll(), close() 메서드 호출 시 자동 커밋
Manual Commit
- 동기 커밋
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecords<String, String> record : records) {
//...
}
try {
consumer.commitSync();
} catch (Exception ex) {
// 커밋 실패 시 에러 발생
}- 비동기 커밋
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecords<String, String> record : records) {
//...
}
consumer.commitAsync();
// 성공여부 확인 필요 시 -> commitAsync(OffsetCommitCallback callback)재처리
- Consumer는 동일한 메시지를 중복해서 조회할 가능성이 있음
- 일시적 커밋 실패, consumer 리밸런스 등
- 따라서, Consumer는 멱등성(idempotence) 고려 필요
- 데이터 특성에 따라 타임스탬프, 일련 변호 등을 활용하여 데이터가 중복 조회되어도 처리가 필요
Session & Heartbeat
- Consumer는 Heartbeat를 전송하여 브로커와 연결을 유지
- 브로커는 일정 시간 Consumer로부터 Heartbeat가 없으면 Consumer Group에서 빼고 리밸런싱 진행
session.timeout.ms: session timeout 시간 (default: 10초)heartbeat.interval.ms: Heartbeat 전송 주기 (default: 3초)session.timeout.ms의 1/3이하 권장
max.poll.interval.ms: poll() 메서드의 초대 호출 간견- 설정 시간이 지나도 poll() 메서드 호출이 없으면 Consumer를 Group에서 빼고 리밸런싱 진행
종료 처리
- 다른 쓰레드에서 wakeup() 메서드 호출
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(prop);
consumer.subscribe(Collections.singleton("simple"));
try {
while (true) {
// wakeup() 호출 시 Exception 발생.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
// records 처리..
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value() + ":" + record.topic() + ":" + record.partition() + ":" + record.offset());
}
try {
consumer.commitAsync();
} catch (Ecception e) {
e.printStackTrace();
}
}
} catch (Exception ex) {
//..
} finally {
consumer.close();
}주의
Kafka Consumer는 쓰레드에 안전하지 않으므로, 여러 쓰레드에서 동시에 사용하면 안 됨.
- wakeup() 메서드는 예외
특징
대용량의 실시간 로그 처리에 특화되어 설계- 기존 범용 메시징 시스템대비
TPS(Transaction per Second)가 매우 우수- 단, 특화된 시스템이기 때문에 범용 메시징 시스템에서 제공하는 다양한 기능들은 제공되지 않음
분산 시스템을 기본으로 설계- 기존 메시징 시스템에 비해 분산 및 복제 구성이 쉬움
- AMQP 프로토콜이나 JMS API를 사용하지 않고 단순한 메시지 헤더를 지닌 TCP기반의 프로토콜을 사용하여
프로토콜에 의한 오버헤드 감소 - 다수의 메시지를
batch형태로 broker에게 한 번에 전달 - 메시지를 기본적으로 메모리에 저장하는 기존 메시징 시스템과는 달리
메시지를 파일 시스템에 저장- 별도의 설정을 하지 않아도 데이터의 영속성(durability)이 보장
- 메시지를 많이 쌓아두어도 성능이 크게 감소하지 않음
- batch 작업에 사용할 데이터를 쌓아두는 용도로도 사용 가능
- 메시지 처리 도중 문제가 발생하였거나 처리 로직이 변경되었을 경우 consumer가 메시지를 처음부터 다시 처리(rewind)하도록 할 수 있음
- 기존의 메시징 시스템에서는 broker가 consumer에게 메시지를 push해 주는 방식(어떤 메시지를 처리해야 하는지 계산하고 어떤 메시지를 처리 중인지 트랙킹)인데 반해, Kafka는 consumer가 broker로부터 직접 메시지를 가지고 가는
pull 방식으로 동작- consumer는 자신의 처리능력만큼의 메시지만 broker로부터 가져오기 때문에 최적의 성능을 낼 수 있음
- broker의 consumer와 메시지 관리에 대한 부담이 경감
- 메시지를 쌓아두었다가 주기적으로 처리하는 batch consumer의 구현이 가능
- 큐의 기능은 기존의 JMS나 AMQP 기반의 RabbitMQ(데이타 기반 라우팅,페데레이션 기능등)등에 비해서는 많이 부족하지만 대용량 메세지를 지원할 수 있는 것이 가장 큰 특징
- 특히 분산 환경에서 용량 뿐 아니라, 복사본을 다른 노드에 저장함으로써 노드 장애에 대한 장애 대응성을 가지고 있기 때문에 용량에는 확실하게 강점
Reference
RabbitMQ
- AMQT 프로토콜을 구현 해놓은 프로그램
- 신뢰성 : 안정성과 성능을 충족할 수 있도록 다양한 기능 제공
- 유연한 라우팅 : Message Queue가 도착하기 전에 라우팅 되며 플러그인을 통해 더 복잡한 라우팅 설정 가능
- 클러스터링 : 로컬네트워크에 있는 여러 RabbitMQ 서버를 논리적으로 클러스터링 할 수 있고 논리적인 브로커도 가능
- 관리 UI로 편리한 관리
- 거의 모든 언어와 운영체제 지원
- 오픈소스이며 상업적 지원
Reference
'Web' 카테고리의 다른 글
| Refactoring With IntelliJ Summary (0) | 2022.07.08 |
|---|---|
| [NoSQL] MongoDB 탐구하기 (0) | 2022.03.27 |
| [우아한 Tech] 우아한 ATDD (0) | 2022.02.22 |
| [IntelliJ] Spring, Maven, Tomcat Setting in Intranet (인트라넷 환경에서 설정) (0) | 2022.02.16 |
| [Kotlin] 코틀린 맛보기 (0) | 2022.01.21 |