
티스토리 뷰
반응형
NAVER 금융 ETF 종목 엑셀 추출
매번 ETF 종목 현재가 검색하는 귀차니즘이 발동하여... NAVER 금융 ETF 페이지 Scraping 을 해보려고 한다.
항상 Scraping 전에 robots.txt 확인이 필요한다.https://finance.naver.com/robots.txt를 확인해보면 Allow: /sise/ 라고 automated scraping 허용이 되는 것을 확인할 수 있다.
Get Chrome Debug Mode Driver
- chrome 을 자동화 모드가 아닌 Debug 모드로 실행
def get_driver(url):
subprocess.Popen(
r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe --remote-debugging-port=9222 --user-data-dir="D:\chrometemp"')
option = Options()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe', options=option) # https://chromedriver.chromium.org/downloads
driver.get(url=url)
driver.implicitly_wait(5)
return driverGet Page Source
etfItemTable은 종목 정보가 출력되는 list
def get_page_source(driver):
return BeautifulSoup(driver.page_source, 'html.parser')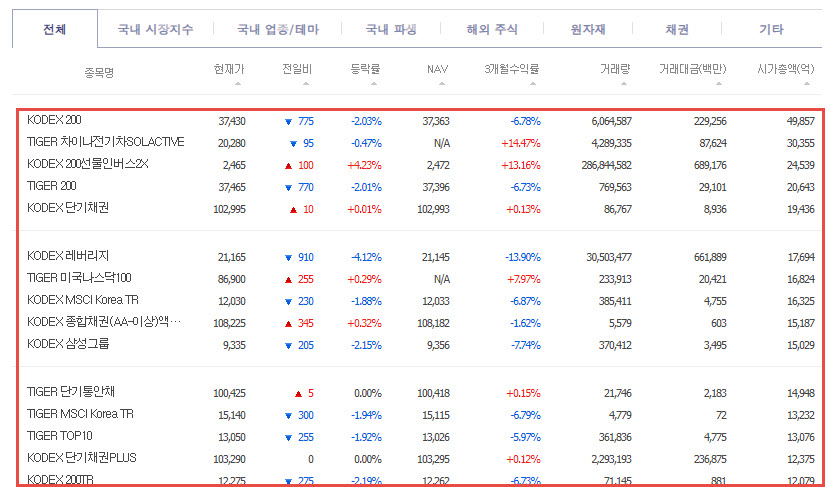
Get Result Data
etfItemTable안에 담긴 모든 종목 정보를 list 에 담아주자.
def get_result_data(page_source):
etf_item_list = page_source.select('#etfItemTable > tr')
code_list = []
name_list = []
cur_price_list = []
previous_day_list = []
fluctuation_rate_list = []
nav_list = []
for item in etf_item_list:
td_list = item.findAll('td')
# non item
if len(td_list) < 9:
continue
code = item.find('a')['href'].split('code=')[-1]
name = item.find('a').text
cur_price = td_list[1].text
previous_day = ''
if td_list[2].text != '0':
state = td_list[2].find('img')['alt']
if state == '상승':
previous_day = '▲'
else:
previous_day = '▼'
previous_day += td_list[2].text
fluctuation_rate = td_list[3].text
nav = td_list[4].text
code_list.append(code)
name_list.append(name)
cur_price_list.append(cur_price)
previous_day_list.append(previous_day)
fluctuation_rate_list.append(fluctuation_rate)
nav_list.append(nav)
data = {
'종목코드': code_list,
'종목명': name_list,
'현재가': cur_price_list,
'전일비': previous_day_list,
'등락률': fluctuation_rate_list,
'NAV': nav_list
}
result_df = pd.DataFrame(data)
return result_dfPrint Favorite Item Info
- 원하는 종목만 따로 출력해서 보고 싶다면 해당 종목 코드들만 list 에 담아보자.
def print_favorite_item(favorite_item_code_list, result_df):
print(result_df[result_df['종목코드'].isin(favorite_item_code_list)]) 종목코드 종목명 현재가 전일비 등락률 NAV
31 360200 KINDEX 미국S&P500 13,890 ▼ 120 -0.86% N/A
17 305720 KODEX 2차전지산업 23,115 ▼ 395 -1.68% 23,087
...Make Data to Excel
- list 에 담긴 종목 정보들을 excel 로 추출해보자.
def make_data_to_excel(root_path, file_name, result_df):
today = str(datetime.today().year) + '.' + str(datetime.today().month) + '.' + str(datetime.today().day) + '_'
result_df.to_excel(root_path + '{0}{1}.xlsx'.format(today, file_name), index=False)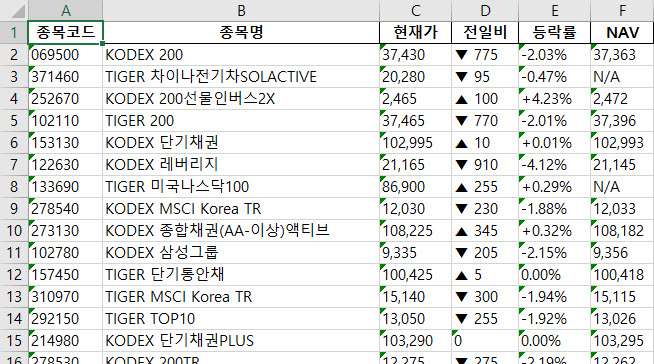
Entire Code
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import subprocess
from selenium.webdriver.chrome.options import Options
import shutil
def get_driver(url):
try:
shutil.rmtree(r"D:\chrometemp")
except FileNotFoundError:
pass
subprocess.Popen(
r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe --remote-debugging-port=9222 --user-data-dir="D:\chrometemp"')
option = Options()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome('C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe', options=option) # https://chromedriver.chromium.org/downloads
driver.get(url=url)
driver.implicitly_wait(5)
return driver
def get_page_source(driver):
return BeautifulSoup(driver.page_source, 'html.parser')
def get_result_data(page_source):
etf_item_list = page_source.select('#etfItemTable > tr')
code_list = []
name_list = []
cur_price_list = []
previous_day_list = []
fluctuation_rate_list = []
nav_list = []
for item in etf_item_list:
td_list = item.findAll('td')
# non item
if len(td_list) < 9:
continue
code = item.find('a')['href'].split('code=')[-1]
name = item.find('a').text
cur_price = td_list[1].text
previous_day = ''
if td_list[2].text != '0':
state = td_list[2].find('img')['alt']
if state == '상승':
previous_day = '▲'
else:
previous_day = '▼'
previous_day += td_list[2].text
fluctuation_rate = td_list[3].text
nav = td_list[4].text
code_list.append(code)
name_list.append(name)
cur_price_list.append(cur_price)
previous_day_list.append(previous_day)
fluctuation_rate_list.append(fluctuation_rate)
nav_list.append(nav)
data = {
'종목코드': code_list,
'종목명': name_list,
'현재가': cur_price_list,
'전일비': previous_day_list,
'등락률': fluctuation_rate_list,
'NAV': nav_list
}
result_df = pd.DataFrame(data)
return result_df
def close_driver(driver):
driver.close()
def make_data_to_excel(root_path, file_name, result_df):
today = str(datetime.today().year) + '.' + str(datetime.today().month) + '.' + str(datetime.today().day) + '_'
result_df.to_excel(root_path + '{0}{1}.xlsx'.format(today, file_name), index=False)
def print_favorite_item(favorite_item_code_list, result_df):
print(result_df[result_df['종목코드'].isin(favorite_item_code_list)])
def run():
URL = 'https://finance.naver.com/sise/etf.nhn'
driver = get_driver(URL)
page_source = get_page_source(driver)
result_df = get_result_data(page_source)
close_driver(driver)
favorite_item_code_list = ['360200', '305720']
print_favorite_item(favorite_item_code_list, result_df)
make_data_to_excel('C:\\Users\\Cristoval\\Desktop\\', 'etf_result', result_df)
if __name__ == '__main__':
run()반응형
'Python' 카테고리의 다른 글
| [Python] Json Type 로그 파일 분석 (0) | 2021.12.18 |
|---|---|
| [NLP] Korean spacing Model (takos-alpha) (0) | 2021.12.04 |
| [Python] Scrape Linkedin People Search Results with Python (링크드인 인물 결과 크롤링) (0) | 2021.11.26 |
| [Python] MS-SQL 연동 (pymssql) SELECT, INSERT, UPDATE, DELETE (0) | 2021.11.21 |
| [자연어처리] Subword Tokenizer (BPE, SentencePiece, Wordpiece Model) (0) | 2021.10.12 |
댓글