
티스토리 뷰
Python
[Python] Scrape Linkedin People Search Results with Python (링크드인 인물 결과 크롤링)
Aaron 2021. 11. 26. 20:50반응형
Scrape Linkedin People Search Results with Python
먼저 scraping 하고자 하는 링크는 https://www.linkedin.com/search/results/people/?keywords.. 이고
https://www.linkedin.com/robots.txt 에 접속해서 automated scraping 허용 여부를 확인해보자.
Disallow 목록에 포함되지 않는다면 시작 !!
Run Chrome Debug mode
- chrome 을 자동화 모드가 아닌 Debug 모드로 실행
subprocess.Popen(
r'C:\Program Files\Google\Chrome\Application\chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\chrometemp"')
option = Options()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome('C:\Program Files\Google\Chrome\Application\chromedriver.exe', options=option) # https://chromedriver.chromium.org/downloads
driver.implicitly_wait(10)Login
- 사용자 검색을 위해 Linkedin 로그인이 필요하다.
# Linkedin 로그인 페이지 이동
URL = 'https://www.linkedin.com/login/ko?fromSignIn=true&trk=guest_homepage-basic_nav-header-signin'
driver.get(url=URL)
driver.implicitly_wait(5)
driver.find_element_by_id('username').send_keys('username') # ID 입력
driver.find_element_by_id('password').send_keys('password') # PW 입력
search_btn = driver.find_element_by_css_selector('#organic-div > form > div.login__form_action_container > button') # button element
search_btn.click()Enter the search keyword
- 검색 키워드 입력
keyword = 'backend developer'
URL = 'https://www.linkedin.com/search/results/people/?keywords=' + keyword
driver.get(url=URL)
driver.implicitly_wait(5)Find the last page
- 검색 결과 마지막 페이지 번호 찾기
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)") # 페이지 하단으로 스크롤
time.sleep(2)
soup_date_detail = BeautifulSoup(driver.page_source, 'html.parser')
last_page = soup_date_detail.select('li.artdeco-pagination__indicator span')[-1].textSearch Results Structure
Structure
People Search Results List Structure
- 사용자 검색 결과 리스트는 아래와 같이
<ul><li>태그로 구성되어 있다.
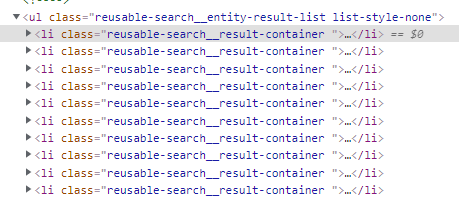
- 사용자 검색 결과 리스트는 아래와 같이
People Profile Structure


- Name Structure
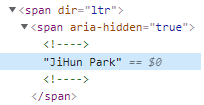
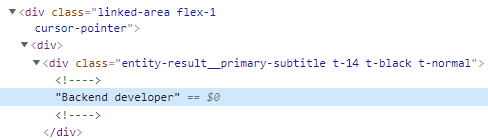
- subtitle Structure
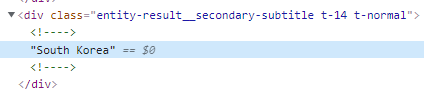
- secondary subtitle Structure
- summary Structure
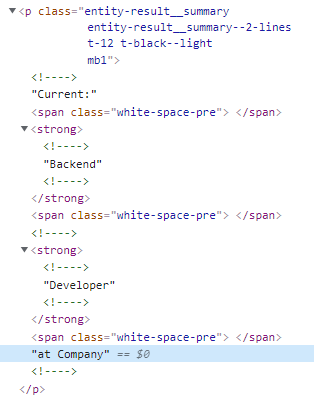
Start Scraping
- name, company, nationality, summary 정보가 없는 경우 exception 이 터져서 try-except 에 담아두긴 했지만 이 부분은 더 개선할 수 있을 듯 보인다.
name_list = []
company_list = []
nationality_list = []
summary_list = []
for page in tqdm(range(1, int(last_page) + 1)):
URL = 'https://www.linkedin.com/search/results/people/?keywords=' + keyword + '&origin=CLUSTER_EXPANSION&page=' + str(page) +'&\sid=luH'
driver.get(url=URL)
driver.implicitly_wait(5)
soup_date_detail = BeautifulSoup(driver.page_source, 'html.parser')
user_list = soup_date_detail.select('div.entity-result__content')
for user in user_list:
try:
name = user.find('span', {'aria-hidden': 'true'}).text.strip()
except:
name = ''
try:
company = user.find('div', {'class': 'entity-result__primary-subtitle'}).text.strip()
except:
company = ''
try:
nationality = user.find('div', {'class': 'entity-result__secondary-subtitle'}).text.strip()
except:
nationality = ''
try:
summary = user.find('p', {'class': 'entity-result__summary'}).text.strip()
except:
summary = ''
name_list.append(name)
company_list.append(company)
nationality_list.append(nationality)
summary_list.append(summary)
driver.close()Extract Excel
data = {
'name': name_list,
'company': company_list,
'nationality': nationality_list,
'summary': summary_list,
}
result_df = pd.DataFrame(data)
result_df.to_excel('C:\\Users\\cristoval\\Desktop\\' + '{0}.xlsx'.format(keyword), index=False)Entire Code
from selenium import webdriver
import pandas as pd
from tqdm import tqdm
import subprocess
from selenium.webdriver.chrome.options import Options
import shutil
import time
from bs4 import BeautifulSoup
try:
shutil.rmtree(r"c:\chrometemp")
except FileNotFoundError:
pass
subprocess.Popen(
r'C:\Program Files\Google\Chrome\Application\chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\chrometemp"')
option = Options()
option.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome('C:\Program Files\Google\Chrome\Application\chromedriver.exe', options=option) # https://chromedriver.chromium.org/downloads
driver.implicitly_wait(10)
# Linkedin 로그인 페이지 이동
URL = 'https://www.linkedin.com/login/ko?fromSignIn=true&trk=guest_homepage-basic_nav-header-signin'
driver.get(url=URL)
driver.implicitly_wait(5)
# 로그인
driver.find_element_by_id('username').send_keys('username') # ID 입력
driver.find_element_by_id('password').send_keys('password') # PW 입력
search_btn = driver.find_element_by_css_selector('#organic-div > form > div.login__form_action_container > button') # button element
search_btn.click()
# Search Keyword
keyword = 'backend developer'
URL = 'https://www.linkedin.com/search/results/people/?keywords=' + keyword
driver.get(url=URL)
driver.implicitly_wait(5)
# Find the last page
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
time.sleep(2)
soup_date_detail = BeautifulSoup(driver.page_source, 'html.parser')
last_page = soup_date_detail.select('li.artdeco-pagination__indicator span')[-1].text
# Start Scraping
name_list = []
company_list = []
nationality_list = []
summary_list = []
for page in tqdm(range(1, int(last_page) + 1)):
URL = 'https://www.linkedin.com/search/results/people/?keywords=' + keyword + '&origin=CLUSTER_EXPANSION&page=' + str(page) +'&\sid=luH'
driver.get(url=URL)
driver.implicitly_wait(5)
soup_date_detail = BeautifulSoup(driver.page_source, 'html.parser')
user_list = soup_date_detail.select('div.entity-result__content')
for user in user_list:
try:
name = user.find('span', {'aria-hidden': 'true'}).text.strip()
except:
name = ''
try:
company = user.find('div', {'class': 'entity-result__primary-subtitle'}).text.strip()
except:
company = ''
try:
nationality = user.find('div', {'class': 'entity-result__secondary-subtitle'}).text.strip()
except:
nationality = ''
try:
summary = user.find('p', {'class': 'entity-result__summary'}).text.strip()
except:
summary = ''
name_list.append(name)
company_list.append(company)
nationality_list.append(nationality)
summary_list.append(summary)
driver.close()
data = {
'name': name_list,
'company': company_list,
'nationality': nationality_list,
'summary': summary_list,
}
result_df = pd.DataFrame(data)
result_df.to_excel('C:\\Users\\cristoval\\Desktop\\' + '{0}.xlsx'.format(keyword), index=False)반응형
'Python' 카테고리의 다른 글
| [NLP] Korean spacing Model (takos-alpha) (0) | 2021.12.04 |
|---|---|
| [Python] NAVER 금융 ETF 종목 크롤링 and 엑셀 추출하기(selenium, BeautifulSoup) (0) | 2021.11.30 |
| [Python] MS-SQL 연동 (pymssql) SELECT, INSERT, UPDATE, DELETE (0) | 2021.11.21 |
| [자연어처리] Subword Tokenizer (BPE, SentencePiece, Wordpiece Model) (0) | 2021.10.12 |
| 파이썬 멀티프로세싱 (Python Multiprocessing) (0) | 2021.08.23 |
댓글