
티스토리 뷰
반응형
CLOVA Speech API
음성을 텍스트로 추출하기 위한 API 중 NAVER CLOVA Speech API 를 활용해보자.
사실 API Documentation 을 보면 엄청나게 친절하게 설명이 되어 있다. (해당 포스팅은 링크 참고용으로 느껴질 만큼....)
참고로 API 요청 후 응답까지 10초 정도 소요되었다.
Ready
결제수단등록
https://www.ncloud.com/mypage/billing/payment
CLOVA Speech 이용 신청
https://www.ncloud.com/product/aiService/clovaSpeech
Object Storage 이용 신청 및 버킷 생성
https://www.ncloud.com/product/storage/objectStorage
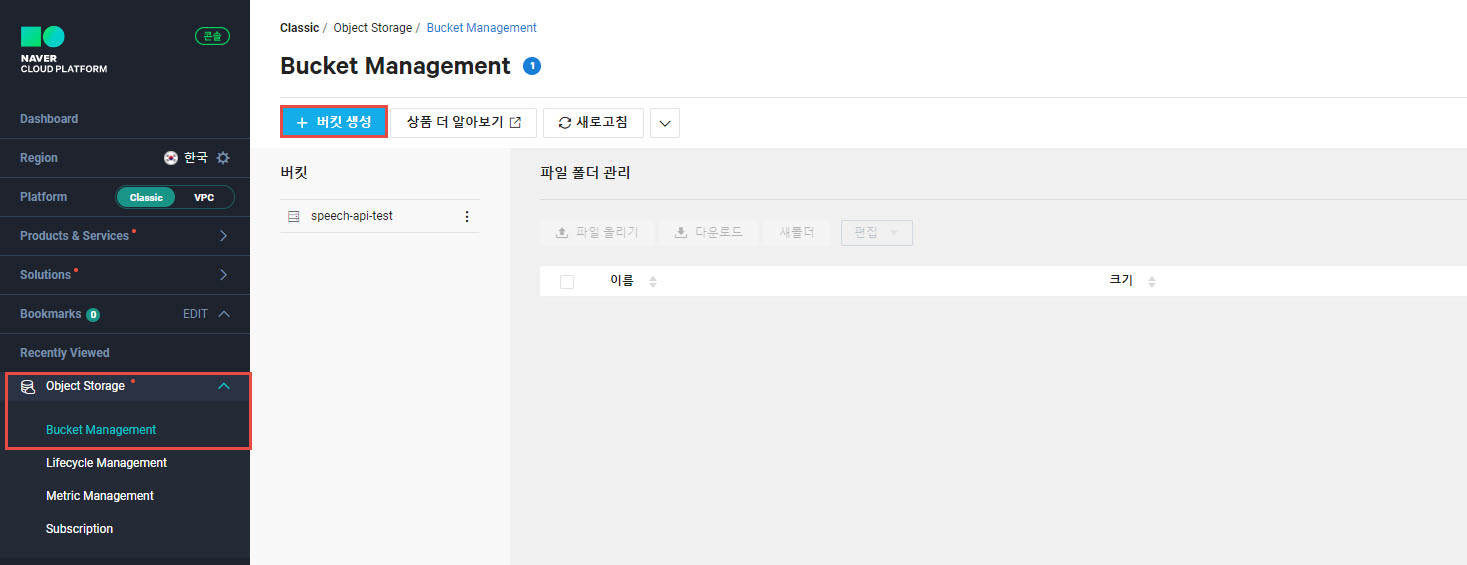
- CLOVA Speech 상품의 필수 연동 상품이라고 하니, CLOVA Speech API 사용을 위해 필수로 이용 신청이 필요하다.
- 이용 신청 후 버킷 생성을 하자.
- 사실 object storage 파일 url로 인식 요청을 하는게 아니면 굳이 Object Storage 이용신청을 할 필요가 있나 싶은데.. CLOVA Speech 도메인 등록을 하려면 필수 입력 항목이라 어쩔 수 없이...
CLOVA Speech 도메인 생성
- NAVER CLOUD PLATFORM Dashboard > Recently Viewd > CLOVA Speech > Domain
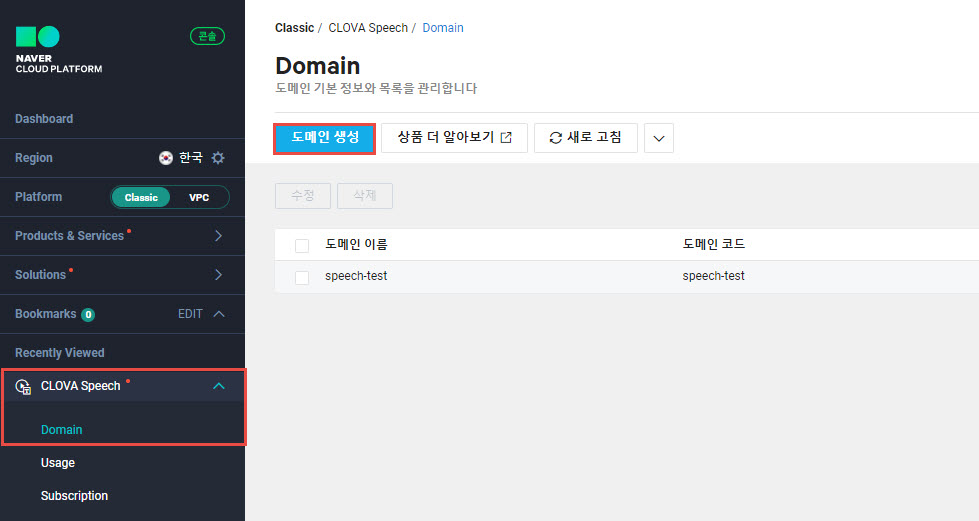
- 도메인 우측 빌더 실행 후 Secret Key 및 CLOVA Speech Invoke URL 확인
API Test
Python
- 자세한 설명은 사실 Documentation 을 참조하는게 빠르고 정확할 듯 싶다...
Request
import requests
import json
class ClovaSpeechClient:
# Clova Speech invoke URL
invoke_url = ''
# Clova Speech secret key
secret = ''
# 외부 url로 인식 요청(외부에서 접속가능한 파일의 고유 url을 이용)
def req_url(self, url, completion, callback=None, userdata=None, forbiddens=None, boostings=None, wordAlignment=True, fullText=True, diarization=None):
request_body = {
'url': url,
'language': 'ko-KR',
'completion': completion,
'callback': callback,
'userdata': userdata,
'wordAlignment': wordAlignment,
'fullText': fullText,
'forbiddens': forbiddens,
'boostings': boostings,
'diarization': diarization,
}
headers = {
'Accept': 'application/json;UTF-8',
'Content-Type': 'application/json;UTF-8',
'X-CLOVASPEECH-API-KEY': self.secret
}
return requests.post(headers=headers,
url=self.invoke_url + '/recognizer/url',
data=json.dumps(request_body).encode('UTF-8'))
# object storage 파일 url로 인식 요청 (object storage에 저장되어 있는 파일의 고유 url을 이용)
def req_object_storage(self, data_key, completion, callback=None, userdata=None, forbiddens=None, boostings=None,
wordAlignment=True, fullText=True, diarization=None):
request_body = {
'dataKey': data_key,
'language': 'ko-KR',
'completion': completion,
'callback': callback,
'userdata': userdata,
'wordAlignment': wordAlignment,
'fullText': fullText,
'forbiddens': forbiddens,
'boostings': boostings,
'diarization': diarization,
}
headers = {
'Accept': 'application/json;UTF-8',
'Content-Type': 'application/json;UTF-8',
'X-CLOVASPEECH-API-KEY': self.secret
}
return requests.post(headers=headers,
url=self.invoke_url + '/recognizer/object-storage',
data=json.dumps(request_body).encode('UTF-8'))
# 로컬의 파일 업로드해서 요청(파일시스템의 경로를 이용)
def req_upload(self, file, completion, callback=None, userdata=None, forbiddens=None, boostings=None,
wordAlignment=True, fullText=True, diarization=None):
request_body = {
'language': 'ko-KR',
'completion': completion,
'callback': callback,
'userdata': userdata,
'wordAlignment': wordAlignment,
'fullText': fullText,
'forbiddens': forbiddens,
'boostings': boostings,
'diarization': diarization,
}
headers = {
'Accept': 'application/json;UTF-8',
'X-CLOVASPEECH-API-KEY': self.secret
}
print(json.dumps(request_body, ensure_ascii=False).encode('UTF-8'))
files = {
'media': open(file, 'rb'),
'params': (None, json.dumps(request_body, ensure_ascii=False).encode('UTF-8'), 'application/json')
}
response = requests.post(headers=headers, url=self.invoke_url + '/recognizer/upload', files=files)
return response
if __name__ == '__main__':
# res = ClovaSpeechClient().req_url(url='http://example.com/media.mp3', completion='sync') # 외부 URI로 인식 요청
# res = ClovaSpeechClient().req_object_storage(data_key='data/media.mp3', completion='sync') # object storage 파일 url로 인식 요청
res = ClovaSpeechClient().req_upload(file='C:\\Users\\jihun.park\\Downloads\\captchaAudio.mp3', completion='sync') # 로컬 파일을 업로드해서 요청
print(res.text)Response
{
"result": "COMPLETED", # 결과 코드
"message": "Succeeded", # 결과 메시지
"token": "a951af6a1015466bae2c926177f26310", # 결과 토큰
"version": "ncp_v2_b28559f_78416aa_20210311_", # 엔진 버전
"params": {
"service": "ncp", # 서비스코드
"domain": "general", # 도메인
"completion": "sync", # 동기/비동기
"callback": "", #
"diarization": {
"enable": true,
"speakerCountMin": -1,
"speakerCountMax": -1
},
"boostings": [
{
"words": "안녕하세요, 테스트"
}
],
"forbiddens": "",
"wordAlignment": true,
"fullText": true,
"priority": 0,
"userdata": {
"_ncp_DomainCode": "NEST",
"_ncp_DomainId": 1,
"_ncp_TaskId": 7218,
"_ncp_TraceId": "c316e0a367bf49f4b3d819538178ac11"
}
},
"progress": 100,
"segments": [
{
"start": 0,
"end": 1110,
"text": "크게 파스.",
"confidence": 0.2,
"diarization": {
"label": "1"
},
"speaker": {
"label": "1",
"name": "A"
},
"words": [
[
160,
440,
"크게"
],
[
520,
1080,
"파스."
]
],
"textEdited": "크게 파스."
}
],
"text": "크게 파스.", # 전체 텍스트
"confidence": 0.2,
"speakers": [
{
"label": "1",
"name": "A"
}
]
}반응형
'Web > API' 카테고리의 다른 글
| [JAVA] 한국어 기초 사전 API 사용하기 (aka. 백과사전 API) (5) | 2021.12.29 |
|---|---|
| [Spring Boot] RESTful API ResponseEntity Example (0) | 2021.12.14 |
| [CLOVA OCR API] NAVER CLOVA OCR API 사용하기 (0) | 2021.10.29 |
| [API] Java JSON Parsing(JSONObject, JSONArray) (0) | 2020.10.17 |
| [API] Java API Connection(HttpURLConnection, JSONObject) (0) | 2020.10.17 |
댓글